Dear Debian community,
this are my bits from DPL written at my last day at another great DebConf.
DebConf attendance
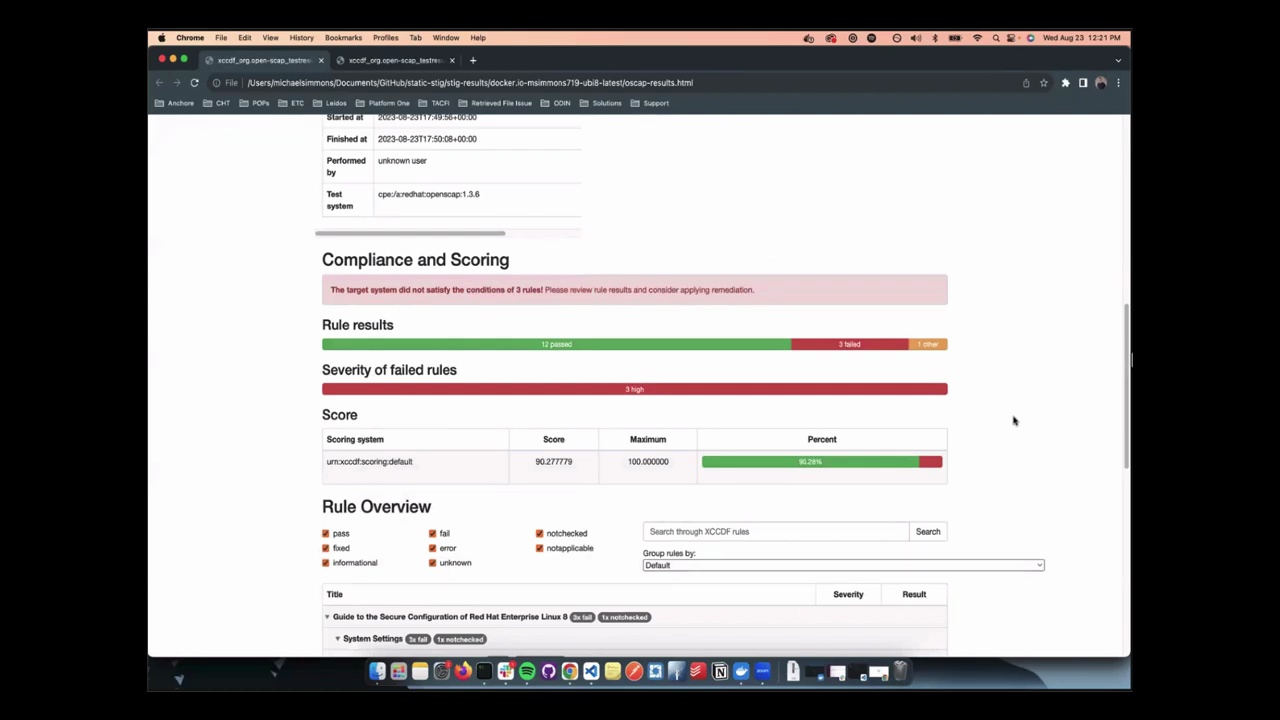
At the beginning of July, there was some discussion with the bursary and content team about sponsoring attendees. The discussion continued at DebConf. I do not have much experience with these discussions. My summary is that while there is an honest attempt to be fair to everyone, it did not seem to work for all, and some critical points for future discussion remained. In any case, I'm thankful to the bursary team for doing such a time-draining and tedious job.
Popular packages not yet on Salsa at all
Otto Kekäläinen did some interesting investigation about Popular packages not yet on Salsa at all. I think I might provide some more up to date list soon by some UDD query which considers more recent uploads than the trends data soon. For instance wget was meanwhile moved to Salsa (thanks to Noël Köthe for this).
Keep on contacting more teams
I kept on contacting teams in July. Despite I managed to contact way less teams than I was hoping I was able to present some conclusions in the Debian Teams exchange BoF and Slide 16/23 of my Bits from the DPL talk. I intend to do further contacts next months.
Nominating Jeremy Bícha for GNOME Advisory Board
I've nominated Jeremy Bícha to GNOME Advisory Board. Jeremy has volunteered to represent Debian at GUADEC in Denver.
DebCamp / DebConf
I attended DebCamp starting from 22 July evening and had a lot of fun with other attendees. As always DebConf is some important event nearly every year for me. I enjoyed Korean food, Korean bath, nature at the costline and other things.
I had a small event without video coverage Creating web galleries including maps from a geo-tagged photo collection. At least two attendees of this workshop confirmed success in creating their own web galleries.
I used DebCamp and DebConf for several discussions. My main focus was on discussions with FTP master team members Luke Faraone, Sean Whitton, and Utkarsh Gupta. I'm really happy that the four of us absolutely agree on some proposed changes to the structure of the FTP master team, as well as changes that might be fruitful for the work of the FTP master team itself and for Debian developers regarding the processing of new packages.
My explicit thanks go to Luke Faraone, who gave a great introduction to FTP master work in their BoF. It was very instructive for the attending developers to understand how the FTP master team checks licenses and copyright and what workflow is used for accepting new packages.
In the first days of DebConf, I talked to representatives of DebConf platinum sponsor WindRiver, who announced the derivative eLxr. I warmly welcome this new derivative and look forward to some great cooperation. I also talked to the representative of our gold sponsor, Microsoft.
My first own event was the Debian Med BoF. I'd like to repeat that it might not only be interesting for people working in medicine and microbiology but always contains some hints how to work together in a team.
As said above I was trying to summarise some first results of my team contacts and got some further input from other teams in the Debian Teams exchange BoF.
Finally, I had my Bits from DPL talk. I received positive responses from attendees as well as from remote participants, which makes me quite happy. For those who were not able to join the events on-site or remotely, the videos of all events will be available on the DebConf site soon. I'd like to repeat the explicit need for some volunteers to join the Lintian team. I'd also like to point out the "Tiny tasks" initiative I'd like to start (see below).
BTW, if someone might happen to solve my quiz for the background images there is a summary page in my slides which might help to assign every slide to some DebConf. I could assume that if you pool your knowledge you can solve more than just the simple ones. Just let me know if you have some solution. You can add numbers to the rows and letters to the columns and send me:
2000/2001: Uv + Wx
2002: not attended
2003: Yz
2004: not attended
2005:
2006: not attended
2007:
...
2024: A1
This list provides some additional information for DebConfs I did not attend and when no video stream was available. It also reminds you about the one I uncovered this year and that I used two images from 2001 since I did not have one from 2000. Have fun reassembling good memories.
Tiny tasks: Bug of the day
As I mentioned in my Bits from DPL talk, I'd like to start a "Tiny tasks" effort within Debian. The first type of tasks will be the Bug of the day initiative. For those who would like to join, please join the corresponding Matrix channel. I'm curious to see how this might work out and am eager to gain some initial experiences with newcomers. I won't be available until next Monday, as I'll start traveling soon and have a family event (which is why I need to leave DebConf today after the formal dinner).
Kind regards from DebConf in Busan Andreas.